linear_reg() |>
set_engine("lm") |> # << Engine set to `lm`
fit(mpg ~ ., data = mtcars) # << Local `mtcars`
tidymodels and Spark
Intro
tidymodels is a collection of packages for modeling and machine learning. Just like sparklyr, tidymodels uses tidyverse principles.
sparklyr allows us to use dplyr verbs to manipulate data. We use the same commands in R when manipulating local data or Spark data. Similarly, sparklyr and some packages in the tidymodels ecosystem offer integration.
As with any evolving framework, the integration does not apply to all functions. This article aims at enumerating what is available today, and why should we consider using the tidymodels implementation in our day-to-day work with Spark.
Our expectation is that this article will be constantly updated as the integration between tidymodels and sparklyr grows and improves.
Model specification with parsnip
parsnip provides a common interface to models. This enables us to run the same model against multiple engines. parsnip contains translation for each of these packages, so we do not have to remember, or find out, how to setup each argument in the respective package.
Why use in Spark?
In some cases, it is better to try out model parameters on a smaller, local, data set in R. Once we are happy with the parameters, we can then run the model over the entire data set in Spark.
For example, doing this for a linear regression model, we would use lm() locally, and then we would have to re-write the model using ml_linear_regression(). Both of these functions have different sets of function arguments that we would need to set.
parsnip allows us to use the exact same set of functions and arguments when running against either back-end. With a couple of small changes, we can change the target engine (R vs Spark) and the target data set (local vs remote). Here is an example of what the model fitting looks like locally in R:
To switch to Spark, we just need to change the engine to spark, and the training data set to the remote Spark data set:
linear_reg() |>
set_engine("spark") |> # << Engine set to `spark`
fit(mpg ~ ., data = spark_mtcars) # << Remote `mtcars`List of supported models
There are six parsnip models that currently support sparklyr equivalent models. Here is the list:
| Model | parsnip function |
Classification | Regression |
|---|---|---|---|
| Boosted trees | boost_tree() |
Yes | Yes |
| Decision trees | decision_tree() |
Yes | Yes |
| Linear regression | linear_reg() |
Yes | |
| Logistic regression | logistic_reg() |
Yes | |
| Multinomial regression | multinom_reg() |
Yes | |
| Random forest | rand_forest() |
Yes | Yes |
Examples
This article will use the same Spark session in all the examples.
library(sparklyr)
library(dplyr)
sc <- spark_connect("local")We will upload the mtcars data set to the Spark session:
spark_mtcars <- copy_to(sc, mtcars)A linear regression model is trained with spark_mtcars:
library(parsnip)
mtcars_model <- linear_reg() |>
set_engine("spark") |>
fit(mpg ~ ., data = spark_mtcars)
mtcars_model
#> parsnip model object
#>
#> Formula: mpg ~ .
#>
#> Coefficients:
#> (Intercept) cyl disp hp drat wt
#> 12.30337416 -0.11144048 0.01333524 -0.02148212 0.78711097 -3.71530393
#> qsec vs am gear carb
#> 0.82104075 0.31776281 2.52022689 0.65541302 -0.19941925It is also possible to see how parsnip plans to translate the model against the given engine. Use translate() so view the translation:
linear_reg() |>
set_engine("spark") |>
translate()
#> Linear Regression Model Specification (regression)
#>
#> Computational engine: spark
#>
#> Model fit template:
#> sparklyr::ml_linear_regression(x = missing_arg(), formula = missing_arg(),
#> weights = missing_arg())Now, we will show an example with a classification model. We will fit a random forest model. To start, we will copy the iris data set to the Spark session:
spark_iris <- copy_to(sc, iris)We can prepare the model by piping the initial setup of 100 trees, then then to set the mode to “classification”, and then the engine to “spark” and lastly, fit the model:
iris_model <- rand_forest(trees = 100) |>
set_mode("classification") |>
set_engine("spark") |>
fit(Species ~., data = spark_iris)
iris_model
#> parsnip model object
#>
#> Formula: Species ~ .
#>
#> RandomForestClassificationModel: uid=random_forest__7b58803e_40f7_41e4_833b_ea47a024f09a, numTrees=100, numClasses=3, numFeatures=4Model results with broom
The broom package offers great ways to get summarized information about a fitted model. There is support for three broom functions in sparklyr:
tidy()- Summarizes information about the components of a model. A model component might be a single term in a regression, a single hypothesis, a cluster, or a class.glance()- Returns a data frame with exactly one row of model summaries. The summaries are typically goodness of fit measures, p-values for hypothesis tests on residuals, or model convergence information.augment()- Adds the prediction columns to the data set. This function is similar toml_predict(), but instead of returning only a vector of predictions (likepredict()), it adds the new column(s) to the data set.augment()
Why use in Spark?
tidy() and glance() offer a very good, concise way to view the model results in a rectangular data frame. This is very helpful when we want to compare different model runs side-by-side.
List of supported models
Currently, 20 Spark models support broom via sparklyr. Here is the current list of models and the corresponding sparklyr function:
Models that support glance(), tidy(), and augment() |
|
| Model | Function |
|---|---|
| ALS | ml_als() |
| Bisecting K-Means Clustering | ml_bisecting_kmeans() |
| Decision Trees | ml_decision_tree() |
| Gaussian Mixture clustering. | ml_gaussian_mixture() |
| Generalized Linear Regression | ml_generalized_linear_regression() |
| Gradient Boosted Trees | ml_gradient_boosted_trees() |
| Isotonic Regression | ml_isotonic_regression() |
| K-Means Clustering | ml_kmeans() |
| Latent Dirichlet Allocation | ml_lda() |
| Linear Regression | ml_linear_regression() |
| LinearSVC | ml_linear_svc() |
| Logistic Regression | ml_logistic_regression() |
| Multilayer Perceptron | ml_multilayer_perceptron() |
| Naive-Bayes | ml_naive_bayes() |
| Random Forest | ml_random_forest() |
| Survival Regression | ml_aft_survival_regression() |
| PCA (Estimator) | ml_pca() |
Examples
Using the same Spark session and models created in the previous section we start by loading broom:
To view the estimates for each term simply pass mtcars_model to the tidy() function:
tidy(mtcars_model)
#> # A tibble: 11 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 12.3 18.7 0.657 0.518
#> 2 cyl -0.111 1.05 -0.107 0.916
#> 3 disp 0.0133 0.0179 0.747 0.463
#> 4 hp -0.0215 0.0218 -0.987 0.335
#> 5 drat 0.787 1.64 0.481 0.635
#> 6 wt -3.72 1.89 -1.96 0.0633
#> 7 qsec 0.821 0.731 1.12 0.274
#> 8 vs 0.318 2.10 0.151 0.881
#> 9 am 2.52 2.06 1.23 0.234
#> 10 gear 0.655 1.49 0.439 0.665
#> 11 carb -0.199 0.829 -0.241 0.812glance() returns the the models R Squared, error means, and variance:
glance(mtcars_model)
#> # A tibble: 1 × 5
#> explained.variance mean.absolute.error mean.squared.error
#> <dbl> <dbl> <dbl>
#> 1 30.6 1.72 4.61
#> # ℹ 2 more variables: r.squared <dbl>,
#> # root.mean.squared.error <dbl>
augment(mtcars_model)For our classification model, tidy() returns each feature’s importance:
tidy(iris_model)
#> # A tibble: 4 × 2
#> feature importance
#> <chr> <dbl>
#> 1 Petal_Width 0.466
#> 2 Petal_Length 0.393
#> 3 Sepal_Length 0.126
#> 4 Sepal_Width 0.0154The glance() model returns the number of trees, nodes depth, sub-sampling rate and impurtiy mode:
glance(iris_model)
#> # A tibble: 1 × 5
#> num_trees total_num_nodes max_depth impurity
#> <int> <int> <int> <chr>
#> 1 100 1478 5 gini
#> # ℹ 1 more variable: subsampling_rate <dbl>
yardstick-like metrics
The metrics() function, from the yardstick package, provides an easy to read tibble with the relevant metrics. It automatically detects the type of model and it decides which metrics to show.
Why use in Spark?
In sparklyr, the family of ml_metrics... functions outputs a tibble with the same structure as yardstick::metrics(). The functions also expect the same base arguments of x, truth and estimate. In sparklyr, model detection is not available yet, so based on the type of model, there are three functions to choose from.
The ml_metrics... functions expect a tbl_spark that was created by the ml_predict() function. These functions provide a metrics argument that allows us to change the metrics to calculate. All of the metrics that have an equivalent in yardstick can be called using the same value, such as f_meas. For others, they can be requested using Spark’s designation. For more information, see the help file of the specific ml_metrics... function.
How are they different form ml_evaluate()?
It is true that both sets of functions return metrics based on the results. The difference is that ml_evaluate() requires the original Spark model object in order to work. ml_metrics... only required a table with the predictions, preferably, predictions created by ml_predict().
Example
Using sdf_random_split(), split the data into training and test. And then fit a model. In this case it will be a logistic regression model.
prep_iris <- tbl(sc, "iris") |>
mutate(is_setosa = ifelse(Species == "setosa", 1, 0))
iris_split <- sdf_random_split(prep_iris, training = 0.5, test = 0.5)
model <- ml_logistic_regression(iris_split$training, "is_setosa ~ Sepal_Length")With ml_predict(), create a new tbl_spark that contains the original data and additional columns needed created by the prediction process.
tbl_predictions <- ml_predict(model, iris_split$test)The ml_metrics_binary() outputs a tibble with the ROC and PR AUC.
ml_metrics_binary(tbl_predictions)
#> # A tibble: 2 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 roc_auc binary 0.960
#> 2 pr_auc binary 0.887Correlations using corrr
The corrr package helps with exploring data correlations in R. It returns a data frame with all of the correlations.
Why use in Spark?
For sparklyr, corrr wraps the ml_cor() function, and returns a data frame with the exact same format as if the correlation would have been calculated in R. This allows us to use all the other functions inside corrr, such as filtering, and plotting without having to re-run the correlation inside Spark.
Example
We start by loading the package corrr:
We will pipe spark_mtcars into the correlate() function. That runs the correlations inside Spark, and returning the results into R. Those results are saved into a data frame:
corr_mtcars <- spark_mtcars |>
correlate()The corr_mtcars variable is now a local data set. So we do not need to go back to Spark if we wish to use it for other things that corrr can do:
corr_mtcars
#> # A tibble: 11 × 12
#> term mpg cyl disp hp drat wt qsec
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 mpg NA -0.852 -0.848 -0.776 0.681 -0.868 0.419
#> 2 cyl -0.852 NA 0.902 0.832 -0.700 0.782 -0.591
#> 3 disp -0.848 0.902 NA 0.791 -0.710 0.888 -0.434
#> 4 hp -0.776 0.832 0.791 NA -0.449 0.659 -0.708
#> 5 drat 0.681 -0.700 -0.710 -0.449 NA -0.712 0.0912
#> 6 wt -0.868 0.782 0.888 0.659 -0.712 NA -0.175
#> 7 qsec 0.419 -0.591 -0.434 -0.708 0.0912 -0.175 NA
#> 8 vs 0.664 -0.811 -0.710 -0.723 0.440 -0.555 0.745
#> 9 am 0.600 -0.523 -0.591 -0.243 0.713 -0.692 -0.230
#> 10 gear 0.480 -0.493 -0.556 -0.126 0.700 -0.583 -0.213
#> 11 carb -0.551 0.527 0.395 0.750 -0.0908 0.428 -0.656
#> # ℹ 4 more variables: vs <dbl>, am <dbl>, gear <dbl>,
#> # carb <dbl>For example, shave() removes the duplicate correlations from the data set, making it easier to read:
corr_mtcars |>
shave()
#> # A tibble: 11 × 12
#> term mpg cyl disp hp drat wt qsec
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 mpg NA NA NA NA NA NA NA
#> 2 cyl -0.852 NA NA NA NA NA NA
#> 3 disp -0.848 0.902 NA NA NA NA NA
#> 4 hp -0.776 0.832 0.791 NA NA NA NA
#> 5 drat 0.681 -0.700 -0.710 -0.449 NA NA NA
#> 6 wt -0.868 0.782 0.888 0.659 -0.712 NA NA
#> 7 qsec 0.419 -0.591 -0.434 -0.708 0.0912 -0.175 NA
#> 8 vs 0.664 -0.811 -0.710 -0.723 0.440 -0.555 0.745
#> 9 am 0.600 -0.523 -0.591 -0.243 0.713 -0.692 -0.230
#> 10 gear 0.480 -0.493 -0.556 -0.126 0.700 -0.583 -0.213
#> 11 carb -0.551 0.527 0.395 0.750 -0.0908 0.428 -0.656
#> # ℹ 4 more variables: vs <dbl>, am <dbl>, gear <dbl>,
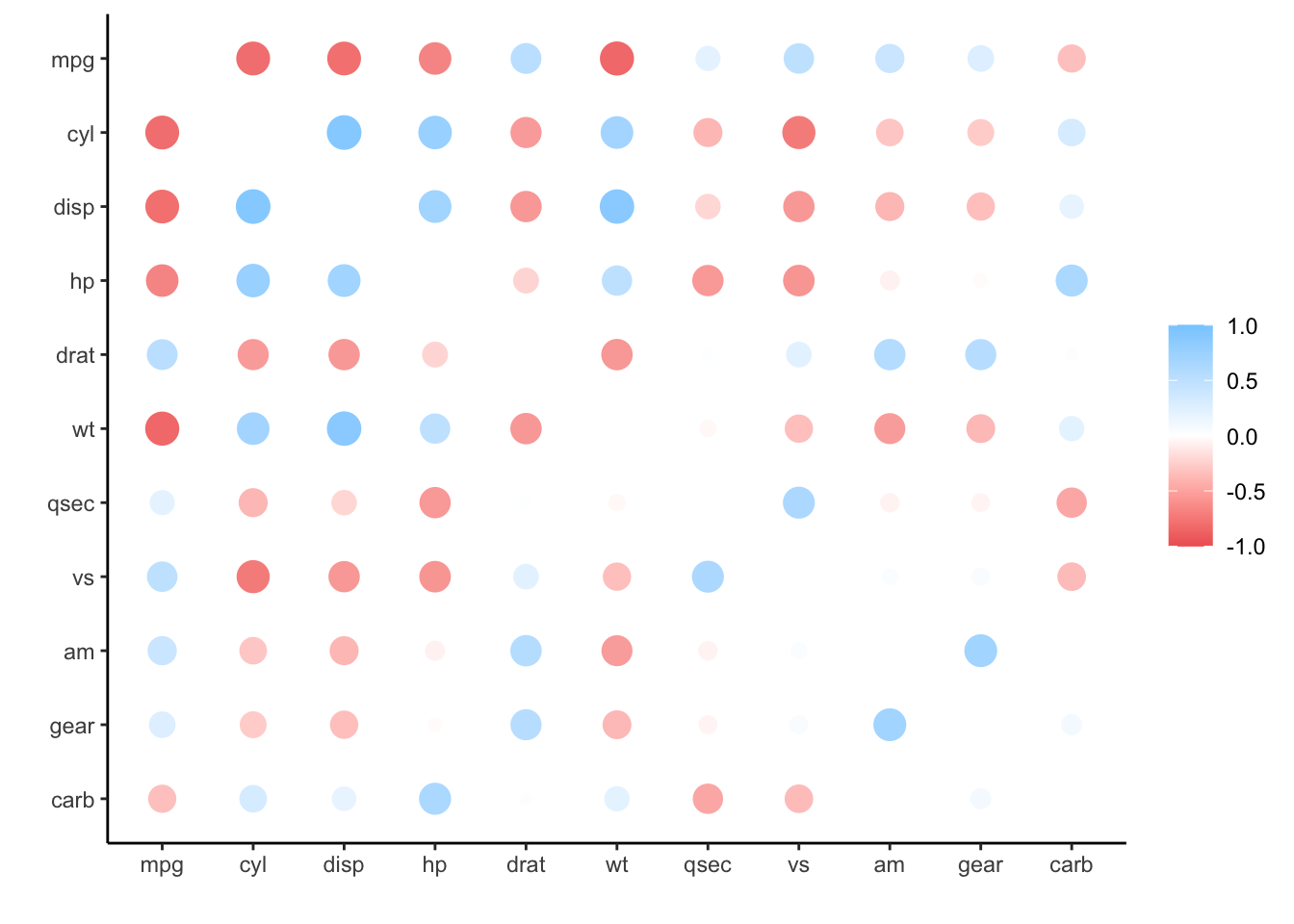
#> # carb <dbl>rplot() provides a nice way to visualize the correlations. Again, because corr_mtcars’s data it is currently locally in R, plotting requires no extra steps:
corr_mtcars |>
rplot()