Using sparklyr with Qubole
Overview
This documentation demonstrates how to use sparklyr with Apache Spark in Qubole along with RStudio Server Pro and RStudio Connect.
Best practices for working with Qubole
-
Manage packages via Qubole Environments - Packages installed via
install.packages()are not available on cluster restart. Packages managed through Qubole Environments are persistent. - Restrict workloads to interactive analysis - Only perform workloads related to exploratory or interactive analysis with Spark, then write the results to a database, file system, or cloud storage for more efficient retrieval in apps, reports, and APIs.
- Load and query results efficiently - Because of the nature of Spark computations and the associated overhead, Shiny apps that use Spark on the backend tend to have performance and runtime issues; consider reading the results from a database, file system, or cloud storage instead.
Using RStudio Workbench with Qubole
The Qubole platform includes RStudio Workbench. More details about how to request RStudio Workbench and access it from within a Qubole cluster are available from Qubole.
The steps for running RStudio Workbench inside Qubole are in the following article: Qubole cluster
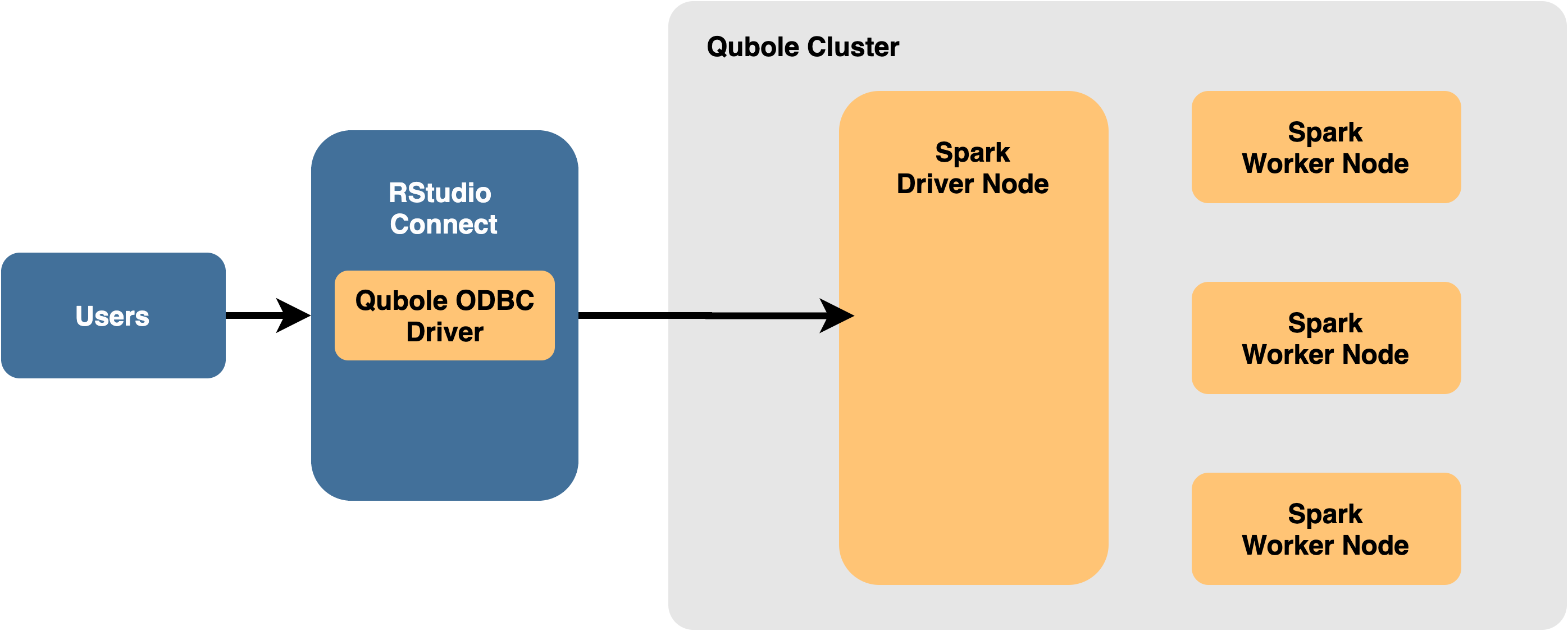
Using RStudio Connect with Qubole
The best configuration for working with Qubole and RStudio Connect is to install RStudio Connect outside of the Qubole cluster and connect to Qubole remotely. This is accomplished using the Qubole ODBC Driver.